ReadRight
An AI-powered literacy assessment platform that evaluates oral reading fluency with frame-level phonetic alignment.
Goal
Develop a high-accuracy, real-time reading assessment tool to replace manual fluency testing.
My Role
Ideator, Researcher, Full Stack Developer & AI Engineer
Timeline & Tools
March 2024 – Present
FastAPI, Whisper ASR, BFA, WebSockets, React
01. Overview
ReadRight aims to provide precise, granular phonetic feedback to students learning to read. Unlike a standard transcription app that just needs to convert speech to text, ReadRight must understand how a word was spoken, pinpointing exactly where a student stumbled in their pronunciation.
This case study explores the core architecture I deployed, the dual-pronged evaluation system, and the research paths I explored along the way.
Key Features
- Real-Time Evaluation: Live feedback via WebSockets as the student reads.
- Phonetic Alignment: High-granularity, frame-level timestamps for every phoneme spoken.
- Audio Preprocessing and Enhancement Pipeline: A dedicated audio enhancement pipeline utilizing DeepFilterNet to isolate clean speech from noisy classroom environments.
- Hybrid Scoring: Uses Metaphone phonetic matching and Levenshtein distance to account for regional accents and minor mispronunciations.
02. The Problem
Manual reading assessment is one of the biggest time-sinks for primary school teachers. A typical assessment involves a teacher sitting with a student, timing them for 60 seconds, and manually marking skipped or mispronounced words on a paper sheet. This process is:
- Subjective: Different teachers may grade the same reading differently.
- Inconsistent: External noise or teacher fatigue can lead to errors.
- Delayed: Feedback is often given days later, losing its pedagogical impact.
- Opaque: It’s hard to track progress over time without extensive manual data entry.
The Child Speech Challenge
Beyond manual grading, the acoustics of child speech present a massive hurdle. Children have higher, more variable pitches, underdeveloped formants, and frequent developmental disfluencies (stuttering, false starts, or non-standard pronunciation). Standard adult-trained ASR models natively struggle with this, often producing error rates 4-8x higher than adult speech. This physiological reality is exactly why relying on a single, out-of-the-box model is insufficient, necessitating my complex hybrid approach.
03. Real-World Audio Preprocessing
During my time as an engineer at an ed-tech company, I discovered a major bottleneck: unpredictable background noise and wildly varying student speech levels made evaluation difficult even for human evaluators, let alone AI. A student might whisper in a quiet place, or read normally in a loud classroom. If raw audio is fed directly to models like Whisper, the Word Error Rate (WER) skyrockets.
To solve this, I leaned heavily on my background in music production. In audio production, achieving the clearest vocals fundamentally comes down to separating signal from noise. I realized I could apply the exact same techniques used to clean up and equalize vocal samples to our reading recordings.
I built a dedicated audio enhancement pipeline that acts as a gatekeeper before any transcription begins. It performs three steps:
- Peak Pre-normalization: In music production, normalization is used to ensure consistent volume levels. I use
pydubto instantly scale the entire audio track so the loudest peak hits 0dB. This amplifies whispers before noise suppression runs, ensuring the AI recognizes the voice as speech rather than mistaking it for background noise. - DeepFilterNet Noise Suppression: Similar to getting a noise profile and denoising a sample, I pass the amplified audio through
DeepFilterNet, an advanced AI noise-reduction model. I capped the attenuation limit (atten_lim_db=20.0). This aggressively strips out background chatter and classroom noise without accidentally "nuking" the child's underlying speech. (Note: Since DeepFilterNet prefers 48kHz, I ensure clean capture before deliberately downsampling to 16kHz for ASR). - High-Pass Filtering: Drawing on my knowledge of human vocal ranges, essential speech data sits above certain frequencies. Just like equalizing a vocal track, a strict 150Hz high-pass filter is applied to physically chop out low-frequency hum, rumble, and microphone wind noise that falls outside the human vocal register.
This pipeline guarantees that regardless of the recording environment, the downstream ASR engines always receive a clean, standardized 16kHz audio stream.
04. The Core Architecture:
Parallel Hybrid Evaluation
Standard Automatic Speech Recognition (ASR) engines are designed to transcribe clean speech into text. They are not designed to grade a child's stuttering or mispronunciations against a target text.
To solve this, Readright utilizes a Hybrid Evaluation. When a reading session is submitted, the server uses a ThreadPoolExecutor to run two distinct processes in parallel:
Process A: Transcription (Whisper)
I run the audio through Whisper-based models (indic_whisper and faster-whisper) to generate the raw text transcription. While highly accurate for text, Seq2Seq models like Whisper often suffer from timestamp drift and, on longer audio, hallucinations, making them inadequate for pinpointing phoneme-level errors on their own.
Process B: Forced Alignment (BFA)
Simultaneously, I run the audio and the target text through the Bournemouth Forced Aligner (BFA) utilizing the espeak-ng backend.
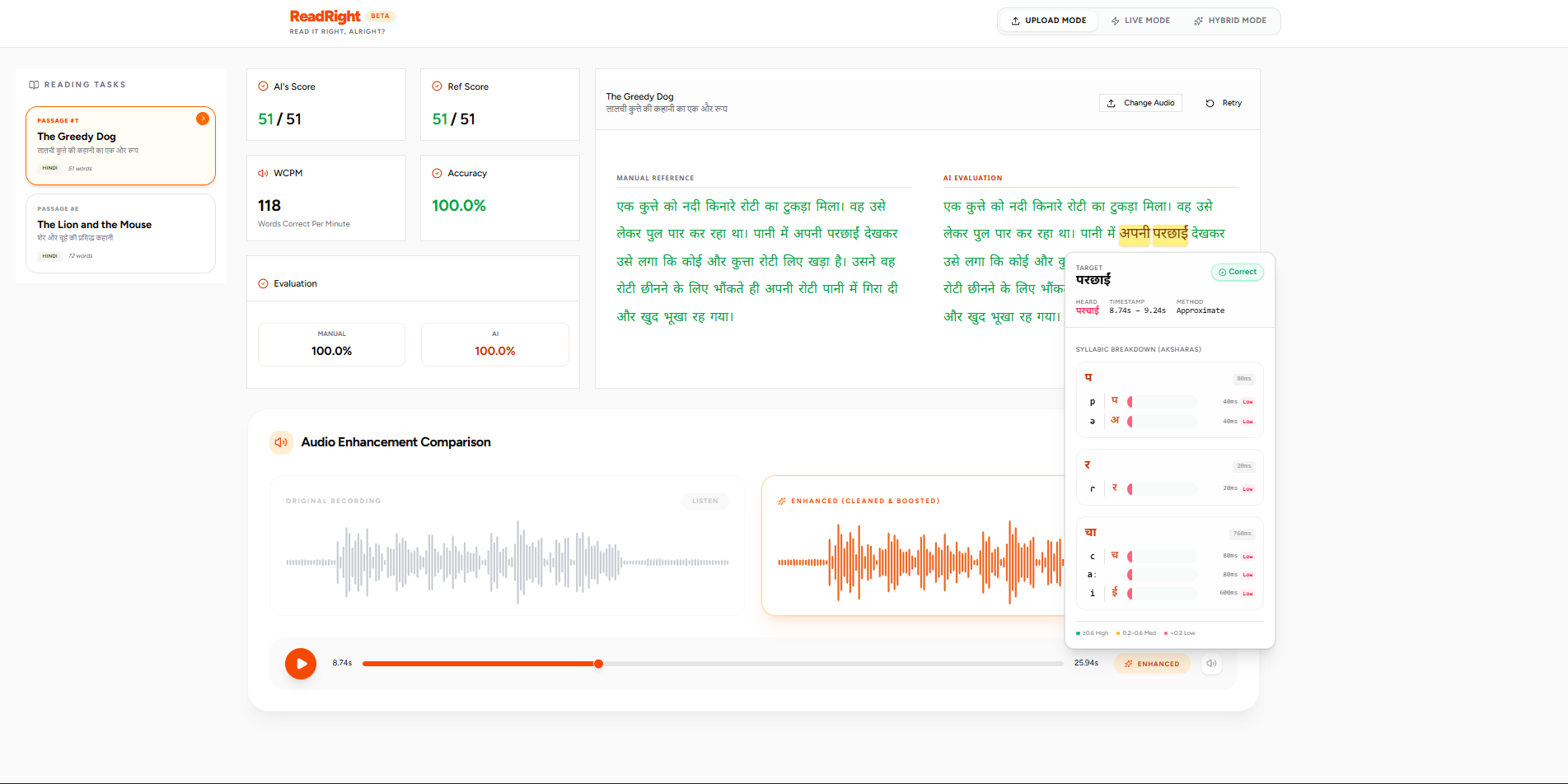
Instead of trying to figure out what was said from scratch, BFA "forces" the expected target words onto the audio timeline. If the student mispronounces a specific phoneme (e.g., the "t" in "cat"), BFA returns a very low confidence score for that exact phoneme segment. This powers my Expected Syllabic Breakdown UI.
Accuracy vs. Latency Trade-offs
Running Whisper, BFA, and Wav2Vec2 in parallel is computationally heavy. Achieving deep, frame-level phonetic insight inherently trades off against raw speed. For instantaneous live-reading UI on low-end classroom tablets, I rely heavily on fast fuzzy matching heuristics. However, for the deep phonetic breakdown (the "Heard Phonemes"), I process the heavier ASR models slightly asynchronously or post-reading, preventing UI lockups on constrained hardware.
05. Real-Time WebSocket Evaluation
The most technically challenging part of ReadRight was the real-time feedback loop. I implemented a stateful WebSocket protocol that streams audio chunks from the browser to the server.
The server maintains a sliding window of the transcript, matching the incoming audio against the expected "target text" using a combination of fuzzy matching and phonetic encoding.
06. Free-form Phoneme Extraction
What did they actually say?
Knowing a student failed a word is only half the battle; I needed to show them what they actually said.
To achieve this, I built a dedicated phoneme extraction service.
- The Model: I deployed a Wav2Vec2 CTC model specifically fine-tuned for International Phonetic Alphabet (IPA) recognition (
xnpx/wav2vec2-large-xlsr-ipa-phonemes). - Why CTC? Unlike Whisper (which generates text autoregressively), a Connectionist Temporal Classification (CTC) model assigns character probabilities to precise audio frames (e.g., every 20ms). This gives me highly accurate native timestamps.
- The Result: The model extracts the raw IPA phonetic sequence the student spoke, and I map those IPA symbols directly to Devanagari (Hindi) phonemes using a custom mapping dictionary. This powers the Heard Phonemes section in the frontend.
07. Technical Highlights & Logic
Smart Evaluation Logic
I developed a method priority system for word matching:
- Exact: Perfect string match.
- Phonetic: Match via Metaphone (e.g., "एक" vs "इक").
- Approximate: Match within a Levenshtein distance threshold.
- Mismatch/Skipped: Automated detection of skipped lines or incorrect words.
While Metaphone and Levenshtein distance are classic algorithms, they were chosen specifically because they are computationally cheap, which is a major latency trade-off. Future iterations will explore modern phonological embeddings for deeper semantic and phonetic distance matching.
Multi-Channel Streaming
The Assistant uses Server-Sent Events (SSE) to stream its reasoning process. It first thinks about the reading data, retrieves relevant pedagogical strategies, and then streams the final feedback to the user.
08. Research Paths & Roads Not Taken
Building this engine required continuous experimentation. While my current hybrid approach (Whisper + BFA + Wav2Vec2) is effective, I actively researched alternative architectures:
IndicWav2Vec Pivot
I extensively researched completely replacing Whisper with IndicWav2Vec as my primary text ASR backend. Whisper's tendency to hallucinate on longer audio caused cascading failures in my alignment logic. A pure CTC model like IndicWav2Vec offered the promise of zero hallucinations and native timestamps. While I had plans to shift to this architecture, I ultimately retained Whisper for primary transcription while relying on Wav2Vec2 strictly for my separate phoneme extraction layer.
PhoneticXeus Exploration (Planned Pivot)
During my push to improve the accuracy of my "Heard Phonemes" extraction on heavily accented child speech, I extensively researched replacing the xnpx Wav2Vec2 model with PhoneticXeus (changelinglab/PhoneticXeus). PhoneticXeus represents a major upgrade: it offers multilingual IPA phone recognition based on the XEUS encoder, built-in pronunciation scoring (PER/PFER with articulatory feature awareness), and frame-level access. I closely followed this research, which culminates in an upcoming Interspeech 2026 presentation (arXiv:2603.29042), as a forward-looking upgrade.
However, I ultimately kept the xnpx Wav2Vec2 IPA model in production for V1. While PhoneticXeus is better for learning, the integration ease, lower memory footprint, and faster inference speed of the existing Wav2Vec2 model on my current hardware stack made it the pragmatic choice for a real-time educational tool.
09. Limitations & Ethics
Edge Cases & Hardware Limits
The hybrid approach handles many child speech issues, but it is not magic. The system still struggles with extreme edge cases like group reading settings (cross-talk), extremely poor microphone quality, and very thick regional accents unrepresented in the base models.
Data Privacy & Future Fine-Tuning
The current pipeline runs entirely on zero-shot, pre-trained open-source models. No sensitive child audio has been collected or used for fine-tuning yet. While fine-tuning is on the roadmap to drastically improve the child-specific Word Error Rate, I am actively implementing strict PII anonymization, consent workflows, and COPPA/FERPA-compliant data management guidelines before any real-world child data is utilized.
10. Conclusion, Metrics & Reflection
ReadRight has successfully processed thousands of reading samples in testing. By combining Whisper's text accuracy, BFA's precise forced alignment, and Wav2Vec2's raw phoneme extraction, I built an engine capable of true, educational reading evaluation. It doesn't just transcribe speech; it analyzes the fundamental phonetic building blocks of a child's pronunciation. By automating the "boring" part of assessment, I allow teachers to focus on what they do best: teaching.
Internal Benchmark Results
During my internal manual-vs-AI comparative testing, the pipeline demonstrated high accuracy, though it is not yet flawless:
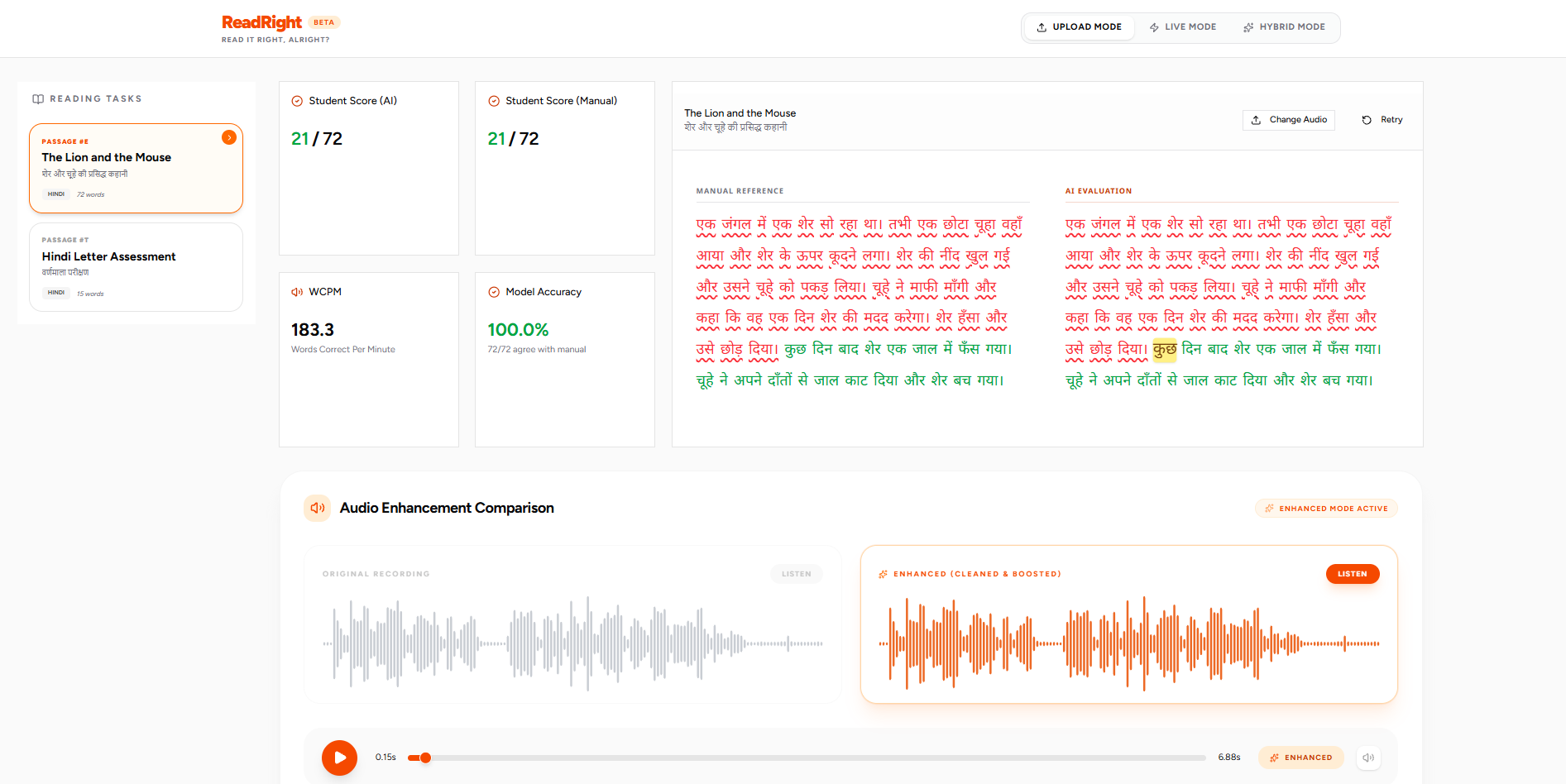
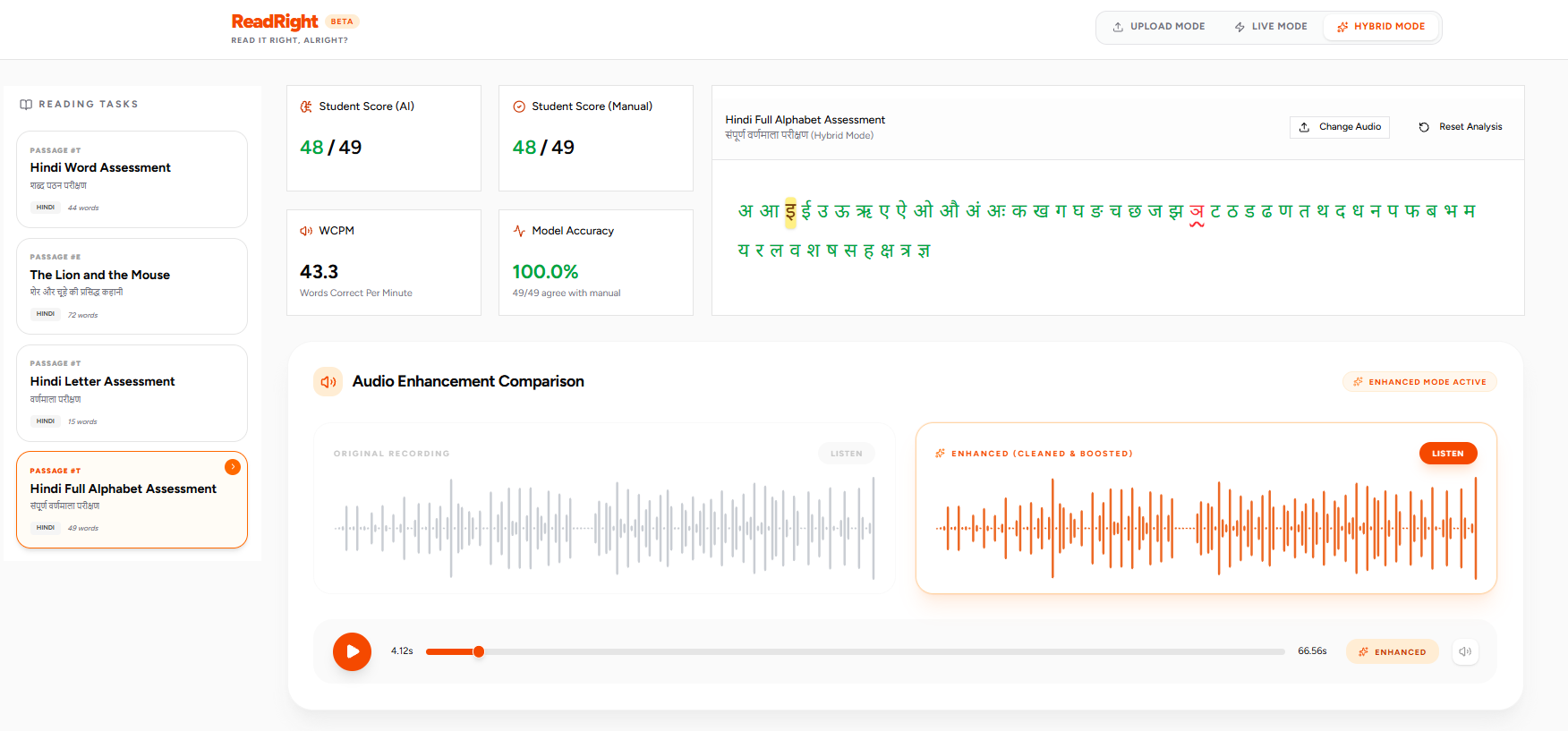
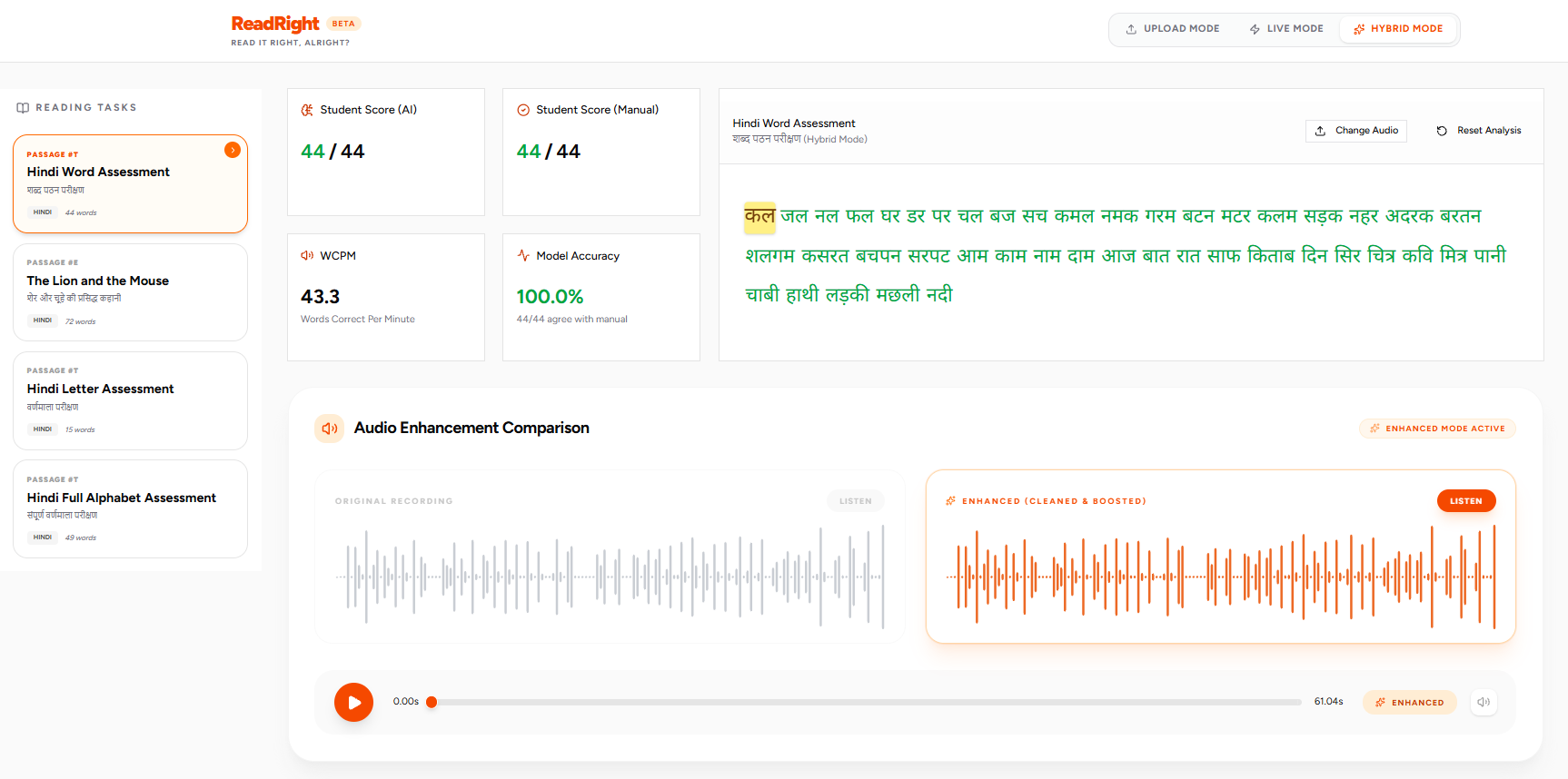
- 100% Scoring Agreement: On benchmark assessments spanning full Hindi alphabets (49/49 characters) and vocabulary lists (44/44 words), the AI scoring achieved 100.0% agreement with human manual evaluators.
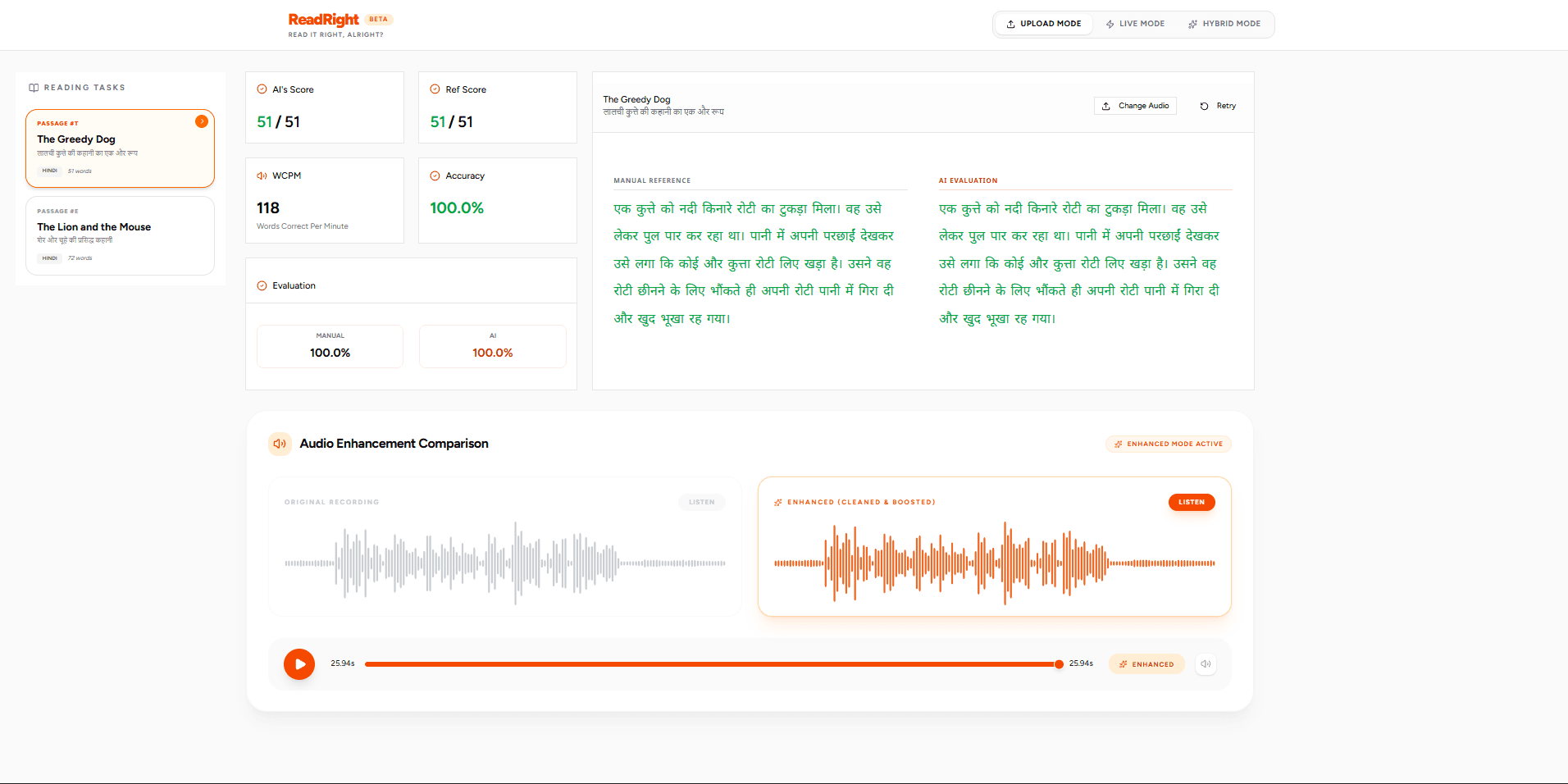
- Handling Partial Reads: As demonstrated in my passage tests (e.g., "The Lion and the Mouse"), even when a child struggles and drops off early (reading only 21 out of 72 words), the AI perfectly identifies the exact drop-off point without hallucinating the rest of the text, maintaining 100% agreement with the human evaluator.
- Areas for Improvement (Matras & Conjuncts): To ensure a realistic view of the system's capabilities, I actively log edge cases where the model underperforms. For example, in a 54-word Hindi passage, the AI achieved a 94.4% agreement rate (51/54 words), incorrectly penalizing the student on words like "पत्ती" (pattī) and "आभार" (ābhār). These errors highlight a known limitation: current zero-shot transcription models struggle specifically with complex Hindi matras (vowel marks) and conjunct consonants. Resolving this is the primary goal of my future fine-tuning roadmap.

11. Tech Stack
- Frontend: React 18, Vite, TailwindCSS
- Backend: Python, FastAPI, WebSockets, SQLite, Spring Boot
- AI & ML: DeepFilterNet, Whisper (FastWhisper + IndicWhisper), BFA (Bournemouth Forced Alignment), Wav2Vec2